視聽組 蘇柏全
摘要 本研究探勘視聽資料借閱紀錄,做為採購影片的參考,提供大專院校圖書館實作及分析參考。研究方法包括:分群法、分類法、聯結法,16,626筆資料中,98%為missing value,因此分析主要針對館藏類型與職稱之間的關係,也就是什麼職務的人會借閱什麼類型的館藏,以及什麼館藏是屬於熱門的館藏等。決策樹演算法分析發現,借出總次數越高時可以被分類於VCD,而錄音帶的借出總次數則越少,反映了目前媒體科技發展的趨勢;分類結果也發現,借閱記錄以大學部的學生為最大宗,借的類型又以雷射唱片為最多,顯示大學生對於提供音樂唱片借閱的服務是相當滿意的,其次則為VCD;教師通常是因為教學而來視聽組借閱,借出的類型以DVD為主;聯結法 (association rule)分析共產生48個法則,準確性較高的法則有:博士後研究通常借閱的館藏類型為DVD(準確性98.9%)、建教合作人員常借閱CD、專任教師常借閱DVD。 |
||||||||||||
1.
序論與動機 隨著科技的日新月異,對於任何資料的儲存,都是隨處可見的,例如各行各業的消費記錄、旅館的住客名單等,而隨著資料被大量儲存,以往被認為是無用的資料,只是記錄交易或者是記錄資料,但對這些看似無用的資料做資料探勘的動作,有時卻可以得到意外有趣的型樣(pattern)與知識。由於此需求,到目前為止產生了許多對於資料探勘上的研究,應用的領域包括:商業管理、生產控制、市場行銷、工程設計和科學探索、醫學等。而在資料探勘上可分為許多部分,如分群、分類、頻繁的型樣探索等,都是許多研究者研究的主題。 資料探勘一般可分為七個步驟:(1)Data cleaning (消除雜亂或不一致的資料)、(2)Data integration (將多種資料來源組合在一起)、(3)Data selection (從資料庫中搜尋分析與任務相關的資料)、(4)Data transformation (將資料轉換或統一成適合探勘的形式)、(5)Data mining (用適當的演算法來對資料做分析)、(6)Pattern evaluation (根據某種interestingness measures,來辨識並表達真正有趣的模式)、(7)Knowledge presentation (使用視覺化和知識表達技術,來向使用者提供探勘出的知識)。如超市交易,透過資料探勘對於銷售記錄的分析,可以得知消費者在買一樣食物時會跟著買那樣飲料,使得市場的銷售人員可以對於物品的擺設以及促銷方案,能夠有更多的資訊以供參考。又例如銀行可以對於過去的金融交易做資料探勘,可以從中得到日後市場走向的資訊,進而幫助客戶迴避風險,做出更有效率的投資。 就圖書館視聽資料採購而言,學校購買院線片、影集、教學用影片等,並未根據過去的借閱資料來做為改進採購影片的參考,若能用以上的資料來做改進,或許可以更能投讀者所好,使同學對學校有更高的認同。因而對借閱記錄做資料探勘重要性不言可喻。本研究應用資料探勘的軟體,利用其中的分群方法、分類方法、聯結法則產生規則,了解借閱記錄是不是能產生一些有趣的型態與法則,像是什麼類型的讀者會借什麼類型的影片、什麼類型的讀者以及什麼性別的讀者的借閱型態等。
2.
相關文獻
2.1
資料探勘 這一節中會對研究中所用到的方法作一些介紹。其中包含了分類分析、群集分析、以及聯結法則分析。 分類分析(Classification Analysis)是從已知類別的物件集合中,依據其屬性(可能影饗物件類別的變數)建立一個分類模式(如決策樹或決策法則),來描述物件屬性與類別之關係,然後再根據這個分類模式對其他未經分類或是新的資料做預測。 群集分析(Clustering Analysis)係指將所有的物件或資料分成若干群集的過程,也就是根據物件間的相似性(或不相似性),將所有的物件分成若干個群集,使得每個群集內的物件具有高度的相似性,而不同群集間具有高度的不相似性。 蒐集一組交易,每一交易包含若干交易項目,聯結分析的目的是由這些交 易資料中,找出交易項目的聯結法則 (Association Rule),此聯結法提供如下列 分析描述「若A、B、C三種交易項目發生時,會發生交易項目D的機率為p, 機率越高表示關連性越高」。 2.2 資料探勘的應用領域 Reinschmidt et al. (1998) 將資料探勘的應用領域,分為三個主要類別如表一所示: 表1:資料探勘的應用領域 (Reinschmidt et al., 1998)
Cabena (1998) 則將應用領域分為行銷管理、風險管理、詐欺管理三方面,如表二所示: 表2:資料探勘應用領域 (Cabena, 1998)
3.
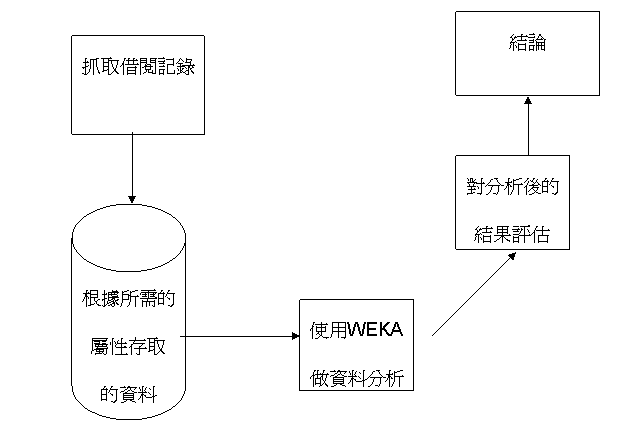
研究流程 以下為本研究的流程圖:
3.1 資料的準備 首先利用圖書館的Innopac系統,來獲取所需data mining的dataset。Innopac系統有許多選項可供選擇,原先的構想是希望可以得到一個書目其所有的借閱記錄,如此得到所有的書目的借閱記錄之後,再做data mining的動作。 但向圖書館詢問了解之後,圖書館的資料儲存方面不可能做到這點,因為如果將所有的借閱記錄都儲存的話,那將會是非常龐大的資料量,是不可能儲存全部資料的,因此其作法,有可能是經過一段時間之後就將某個時間點之前的記錄刪除,或者是一本書在這次被借閱之後就將前幾筆做刪除的動作。如此一來,所得到的資料量將變得非常有限,和之前預期可得到的資料有很大的落差。 從Innopac系統中得到關於借閱記錄的資料,其中含有一筆借閱記錄中其上一筆借出人的讀者類型、職稱、性別等資料屬性,也可得到這本書的書名、資料類型、等相關資料,其中經過篩選之後取出 (1)館藏類型、(2)借書總次數、(3)讀者類型、(4)性別、(5)職稱等五項屬性來做進一步的分析。 (1)館藏類型:其中主要有六個數值,20代表DVD,21代表音樂CD,22代表錄影帶,23代表錄音帶, 25代表CD-ROM,30代表VCD。 (2)借書總次數:此屬性會針對每一書目輸出其被借閱的總次數。 (3)讀者類別:此屬性為一書目上次被借閱時借閱人的類別,其中1代表大學班,2代表碩士班,3代表碩士在職專班,4代表博士班,11代表專任教師,21代表博士後研究,22代表助教,25代表專案計畫工作人員,31代表建教合作專任人員,34代表眷屬。 (4)性別:此屬性分為男、女兩類。 (5)職稱:則是與讀者類別相同,而是將此屬性的value由numeric改為nominal的型態。 但由於之前所提到資料量的問題,有關讀者的屬性跑出來的資料量,missing values高達98%,這是一個很大的問題,在16000多筆資料當中,只有200多筆在這些屬性有值,這對分析上會有很大的影響,而且在館藏類型上,之前所做的分類也只有分DVD、VCD、音樂CD、錄影帶等分類,這對於在data mining所找出的pattern以及分類分群時的分析,所找出的pattern也會有很大的影響。 4. 應用的軟體 在應用的軟體上,所選擇的是WEKA這套免費軟體,這套軟體是以JAVA寫成,其中包含了許多關於分群分類的演算法,以及一些統計的分析,網路上也有許多相關的電子書是專門介紹這套軟體的使用方法,由此可知,WEKA在分析統計以及data mining方面的應用應是相當地強大。對於一些簡單大量的資料,這套軟體所能做的相關分析已是相當足夠的了。其所提供的演算法省去了我們在程式設計的麻煩,並且這些演算法種類繁多,可對不同屬性的資料,如numeric(數值型)、nominal(離散型)的資料都可以做分析。Weka系統擁有進行資料挖掘任務的圖形用戶介面,有助於理解模型,是一個實用並且深受歡迎的工具。 5. 資料分析 5.1 Decision Tree的建立 圖2為WEKA打開所抓取的資料,並轉成WEKA所要求的檔案格式之後的畫面: 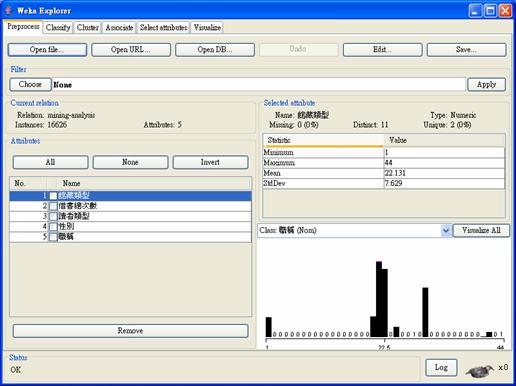
圖2: WEKA開啟資料的畫面 其中對於numeric的資料在右上方的欄位中會顯示出其最大值、最小值、 平均值及標準差,而nominal的資料則會顯示出各個class之間的筆數為何。首先對所抓取的資料做建立decision tree的動作,而建分類時,先對nominal的資料做分類的動作。圖3為經由WEKA的演算法執行之後所顯示的圖片,圖4則為WEKA提供的一個功能,可對decision tree做一個視覺化的動作,而能較清楚的辨別所建出的tree的圖形到底為何,從圖4可以看到經由讀者類型所做出其職稱的分類結果,如果可以取得更多的資料或許能夠在建decision tree時可以做出那一類的讀者可以分到那一類型的影片,但很可惜,目前對於影片的分類資料還不是很充足。 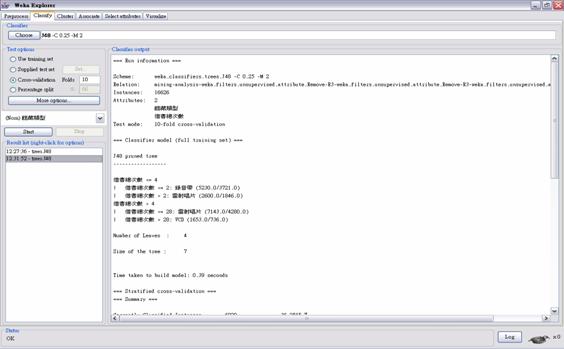
圖3: WEKA建立Decision Tree.
圖4: WEKA建立Decision Tree的視覺化畫面 圖5則是利用借書總次數以及館藏類型兩種屬性值所建出的決策樹的分類結果,其中leave數為4,size為7,這兩個數字分別代表透過決策樹的演算法不斷遞迴可以形成四種分類,而這棵決策樹中所有node的個數為7。由結果可看出當借出總次數越高時可以被分類於VCD,而錄音帶的借出總次數則越少,這也充分反映了目前時代的趨勢。這個結果也可以用來預測一個館藏類型的物品,當其被借閱次數越高時,我們可以預測它是VCD或CD,反之則可以說它可能是錄音帶。 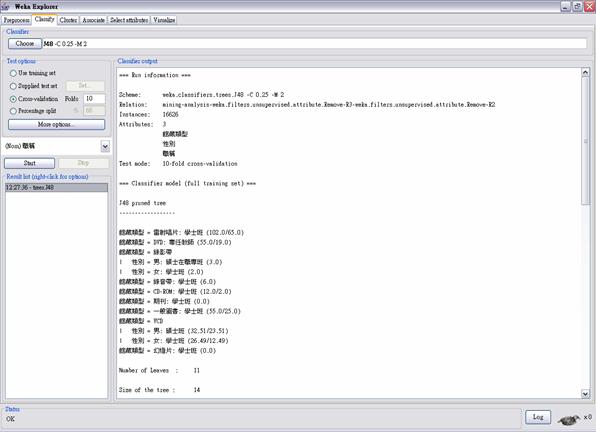
圖5: 利用借書次數以及館藏類型所建出的決策樹分類
針對館藏類型、性別和職稱這三個屬性所做出的決策樹的分類結果,其中leave數為11,size為14,因此我們可以得知透過這決策樹所產生的分類種類有11種,樹的node數共有14個。圖6則是其視覺化的結果。由於WEKA是一免費軟體,其對於視覺化的效果並不是非常理想,當所分類出的結果較多時,圖形會有一些難以識別,這也是其缺點之一。但從文字敘述中仍然可以看出這幾個屬性經過決策樹分類之後的關係為何。從結果可以發現,學校的借閱記錄還是以大學部的學生為最大宗,借的類型幾乎是每種都有,其中又以雷射唱片為最多,因此可以發現學校的同學對於提供音樂CD借閱的這項服務是相當滿意的,其次則為VCD。而專任教師則可分到DVD這個類別,所以可以推測教師通常是因為教學而來視聽組借閱,且借出的類型通常以DVD為主。 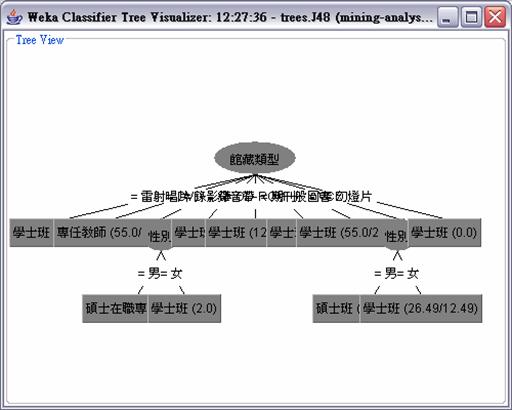
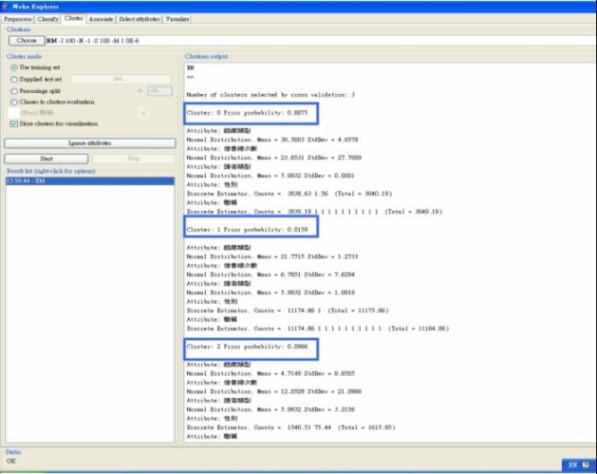
圖6: 針對館藏類型、性別和職稱所做出的決策樹的分類結果 以上的演算法是透過10 Cross-validation所產生出的結果,也就是以10分之9的資料做訓練的動作,用來產生一個分類器的model,再將剩下的10之1的資料做試驗的動作,用之前訓練產生的model來對這些資料做分類。對照實驗所產生的結果,可以說產生出的結果是準確的,因此10 Cross-validation的分類model的預測分類結果是可以接受的。 5.2 Clustering 經由分群演算法,跑出來的結果分為三個cluster。每一個cluster中,我們可以看到這個cluster針對在其中各個attribute的normal distribution mean以及standard deviation。可以看到第一群的先驗機率很高,很明顯是因為資料的miss value的關係。如同之前說過的,所抓取的資料有很大量的miss value,所以不難想見會有這樣的分群結果。另外經由演算法跑出了兩群,由此我們可以得知,雖然職稱的類別有很多,但總體來說,借閱記錄可以分為兩種型態。結果如圖7所示。 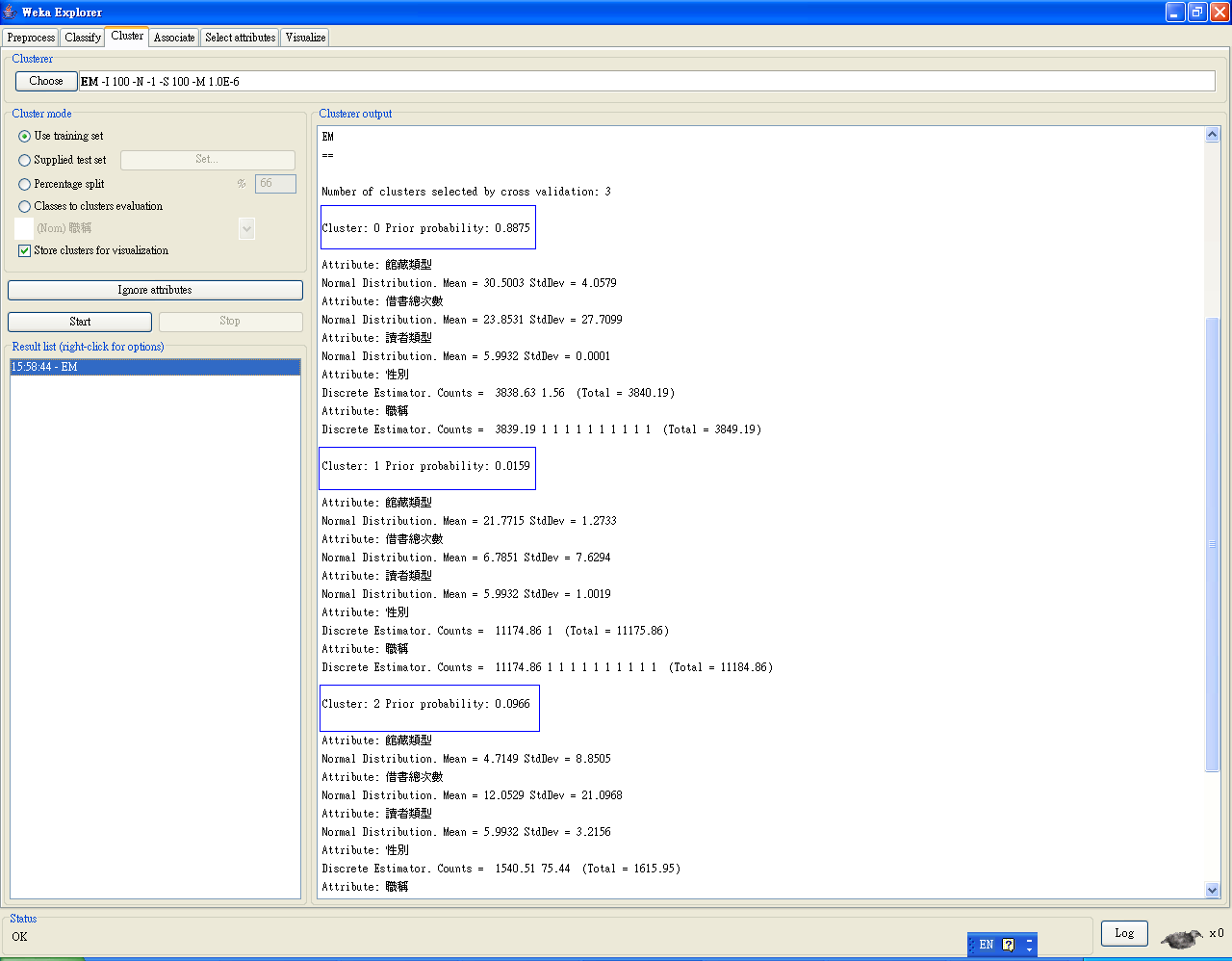
圖7: 借閱記錄的兩種分群 5.3 Association Rule的建立 經由WEKA提供的PredictiveApriori演算法,得到了如圖8associate rule的結果,所謂的associate rule,可以表示為item之間的關聯規則,如超市的一個客戶購買了麵包,則他也會購買牛奶的可能性有多大,這就是associate rule的作用。 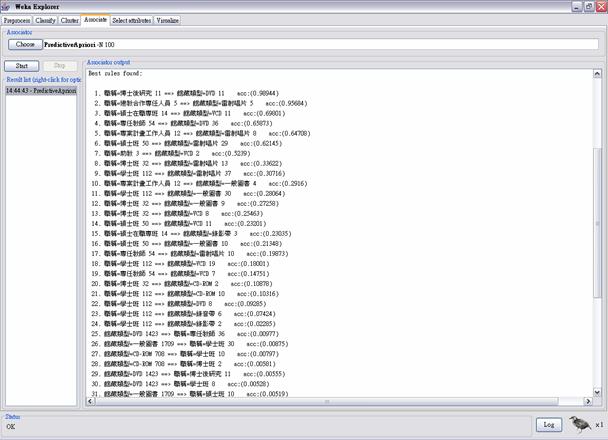
圖8: 借閱紀錄的關聯規則 由跑出來的結果的第一個rule為例,第一個rule為: ”職稱==博士後研究 è 館藏類型==DVD acc(0.98944)” 由這個rule,我們可以得知博士後研究通常借閱的館藏類型為DVD,而且其accuracy高達了98.94%,其他accuracy較高的rule還有建教合作人員常借閱CD、專任教師常借閱DVD,這些都是非常有利於對視聽組的改進的資訊。而透過這個演算法我們總共產生了48個associate rule,最高的accuracy為98.944%,最低的為0.5%。 6. 結論 透過了對視聽資料借閱記錄做探勘,可以了解館藏類型對職稱之間的關係,也就是什麼人會借閱什麼類型的館藏,以及什麼館藏是屬於熱門的館藏等。而如之前所提到的,由於目前借閱記錄資料的不完全,例如:無法得到一個館藏的所有借閱記錄,或是以人為單位的所有借閱記錄,以及為什麼會產生大量的miss values等,都是影響我們分析的原因。如能改善這些不利於資料的因素,相信分析可以得到更多的有用的知識。 文獻參考
1.
Cabena, P., Hadjinian P. and Stadler, R. (1997), Discovering Data Mining From Concept to Implementation, Prentice-Hall Inc.
2.
3.
Han, Jiawei, and Kamber, M. (2001), Data Mining : Concepts and Techniques, Mogan Kaufmann Publishers.
4.
Han, J.,
5.
Pei, J., Han, J., Lu, H., Nishio, S., Tang, S. and Yang, D. (2001), “H-Mine: Hyper-Structure Mining of Frequent Patterns in Large Databases”, ICDM 2001,pp. 441-448.
6.
|
||||||||||||